LEARN THINK BLOG REPEAT
Passkeys Across Domains
There’s a plan for passkeys to work across vendors, but we’re not there yet. Here’s how they can work across domains though, and it works today.
There’s a plan for passkeys to work across vendors, but we’re not there yet. Here’s how they can work across domains though, and it works today.
intro
Last week at the Authenticate conference there was news about a potential path for passkeys to extend beyond the vendor silos in which they currently dwell. But that solution is a bit early, so I thought I’d provide an update about another way passkeys are “breaking out” beyond some historical limitations, and what solutions exist today.
In a previous post, I covered how passkeys (and WebAuthn/FIDO credentials) are resource specific. That means credentials are created per-resource and are tied to the app’s web origin or associated domain equivalent for mobile apps. It’s one of the ways WebAuthn credentials protect privacy. (That’s, of course, in addition to using private keys that are never sent over the wire.)
This privacy protection comes with a couple of trade-offs. First, you end up having a bunch of keys and credentials (we’ve covered that on this blog). Second, it becomes challenging for resources on different domains to use the same credential. Because, well, that’s the whole point! A bunch of different domains shouldn’t be able to use the same credential.
But there are reasons some want to.
This blog post walks through what is and is not possible with passkeys across different domains, including subdomains, domain suffixes and TLDs.
a few terms
In this blog post I make heavy use of a few terms. Here they are, with definitions:
RPID: WebAuthn Relying Party ID, the parameter used optionally in both WebAuthn create() and get() calls
create() and get() calls: WebAuthn compliant API calls exemplified by the browser APIs navigator.credentials.create and navigator.credentials.get(), and corresponding mobile and platform WebAuthn API calls
origin / web origin: the “host” portion of a URL, such as “www.example.com” in “https://www.example.com/”
starting simple
single app on a single domain
Let’s start by looking at how one single domain works with passkeys. To illustrate, I’ve hosted my webauthn test app “Fun with WebAuthN” on my own domain at app.goodsignin.com. (I had to bump myself up from the free to the basic pricing tier to add a custom domain!) Importantly, the DNS is an A record so that the web origin of the app is the custom domain name:
Webauthn sample web app with web origin app.goodsignin.com
enroll a passkey
By default, if I enroll a credential there, the RPID associated with the credential will be app.goodsignin.com. This is because the default RPID associated with a passkey is the app’s web origin.
Windows Hello passkey for RPID app.goodsignin.com
use the passkey
If I then return to the same app to sign in (the app hosts both registration and sign on at the same domain app.goodsignin.com), I will be able to use my new Windows Hello passkey for username 23887@goodsignin.com.

Passkey signin prompt in Chrome browser for local Windows Hello credential
I won’t be able to use this credential anywhere else: just app.goodsignin.com.
adding a twist - domains and subdomains
passing the ‘RPID’ parameter
Keeping the same app in the same place (app.goodsignin.com), now lets enroll a second credential. Only this time, I’ll send the RPID parameter as part of the navigator.credentials.create request. And, instead of app.goodsignin.com, I’ll send as RPID the domain suffix goodsignin.com (the spec allows you to do this).
Public key credential creation options object showing RPID parameter “goodsignin.com”
enrolled passkey
This results in a passkey for user 39008@goodsignin.com with RPID goodsignin.com:
Windows Hello passkey for RPID goodsignin.com
using the passkey(s)
When I come back to the app to sign in, I can use either of the passkeys I created above. The only trick is that, to use the goodsignin.com credential, I have to make sure I provide goodsiginin.com as the RPID parameter in the sign on request, just as I did for creation.
Public key credential request options object showing RPID parameter “goodsignin.com”
So, depending on whether I pass the RPID parameter as shown above, the same app at the same origin will prompt me for the new 39008@goodsignin.com passkey or the original 23887@goodsignin.com passkey, as shown below:


summary: RPID parameter with subdomains
With this trick, one can imagine a company with tons of subdomains under example.com: benefits.example.com, shop.example.com, www.example.com, whatever you want. You will have a way to enroll a passkey that works across all. You just have to remember to:
Send RPID parameter “example.com” on the webauthn create call
Send RPID parameter “example.com” on each webauthn get call across all the subdomains/properties.
Great so far, right?
wait - does this mean i can just create passkeys for a popular subdomain or tld?
Thankfully no.
public domain suffix
This is because azurewebsites.net is a public domain suffix (and not a registrable one, per the WebAuthn spec terminology). Public domain suffixes are on a well known list that is excluded by the WebAuthn protocol because they allow people to register subdomains under them. To illustrate, let’s try to use the trick we used above to create passkeys that will work for subdomains under azurewebsites.net (a Microsoft domain where Azure customers can host web apps.)
First, I’ve hosted the same web app we used above at funwithwebauthn.azurewebsites.net

Webauthn sample web app with web funwithwebauthn.azurewebsites.net
attempting to enroll a passkey for the public suffix
We’ll go ahead and try sending suffix “azurewebsites.net” as the RPID:
Public key credential creation options object showing RPID parameter “azurewebsites.net”
security error
Only this time, when we try to send RPID “azurewebsites.net”, we get the error message “WebAuthn create had an error: The relying party ID is not a registrable domain suffix of, nor equal to the current domain. Subsequently, an attempt to fetch the .well-known/webauthn resource of the claimed RP ID failed.”

Webauthn client returns a SecurityError in response to RPID azurewebsites.net
summary: public domain suffixes and the ‘RPID’ parameter
So, to recap, no, you can’t use a publicly shared domain suffix like azurewebsites.net, github.io, etc as a passkey RPID.
For passkeys, you can and should use as RPID a domain that you own and for which you control who can register sub-domains.
Ok, great. So now we know the domain suffix override cannot be abused. However it still has limitations. It does not allow for the internationalization of goodsiginin.com into goodsignin.co.uk, etc, because these are not domain suffixes but completely distinct domains.
passkeys across disparate domains
Goodsignin.com has gone international! We now have goodsignin.co.uk, goodsignin.ch, goodsignin.kr, … you get the picture.
The scheme I described above breaks because these new domains are disparate domains, meaning they do not share common domain suffixes at all. What can be done?
federation vs related origin requests
Now, the official FIDO people strongly recommend that you use federation. This means enrolling and using passkey credentials at one common domain address (think login.example.com), and then issuing tokens from that site to other relying party sites. Various federation protocols such as OAuth/OpenID Connect, SAML, and WS-Federation can accomplish this. This however means that you are not using WebAuthn/FIDO protocols to sign in to the relying party sites. Rather, you’re back in token land and therefore subject to token compromise.
The other option is to use a new capability that has emerged in the WebAuthn world this year, called related origin requests.

Related origins for app.goodsignin.com
about related origins
Related origins is a way to have a family of disparate domains all able to use the same passkey credential for a user.
This is done by posting a list of origins at a publicly defined, well known endpoint, as pictured above. Related origins are defined in the latest version of the WebAuthn specification. So far, they’re supported in Chrome and Edge on most devices, as you can see under “Advanced Capabilities” on the passkeys.dev device support page.
With related origins, you can choose one “home” domain – it could be for example login.example.com, or example.com, or something completely else. This domain origin will do two things:
Host metadata at endpoint “https://{home domain}/.well-known/webauthn” that specifies a list of origins allowed to use passkeys bound to the home origin (see the image above for example and format)
Serve as the RPID that will be bound to enrolled passkeys, across all of the related domains
Let’s walk through it.
how it works - example
Let’s say I have both of the two WebAuthn relying party apps mentioned above live, respectively, at the domains app.goodsignin.com and funwithwebauthn.azurewebsites.net. For example purposes, these are our disparate domains (I don’t actually own goodsignin.co.uk or any of the others, sorry).
I have related origins JSON metadata hosted on app.goodsignin.com, as shown in the image above.
Now, I enroll a passkey at funwithwebauthn.azurewebsites.net, specifying app.goodsignin.com as RPID.
As a result, I have a new passkey that I can use:
- at the funwithwebauthn.azurewebsites.net app (provided the request specifies RPID app.goodsignin.com)
- at app.goodsignin.com (without the RPID parameter)
That’s it! It’s almost so easy it’s confusing.
So how is this enabled?
how it works - flow
When a WebAuthn request using related origins is processed, the following happens:
1) If an RPID parameter is passed in the options object, either for create or get, the WebAuthn client evaluates it as the intended RPID
if the passed RPID matches the app’s actual web origin, all is good and the RPID value is used for the request
if not, but if the passed RPID it is a non-public domain suffix of the actual web origin, all is good and the RPID value is used for the request
Failing both of the above, the passed RPID value is used to construct the well-known related origins URL (pre-pended with “https://” and appended with “/.well-known/webauthn”) and that endpoint is checked for an entry containing the current site’s actual web origin. If a matching entry is found, all is good and the passed RPID value is used for the WebAuthn request.
2) Unless another error occurs (failed user verification, authenticator not found, etc) the RPID resulting from step 1 above will be either
(for create requests) associated with the new WebAuthn credential, or
(for get requests) used to find the credential and generate a WebAuthn assertion.
3) Importantly, irrespective of the passed RPID, it is the app’s real web origin that is returned in the clientDataJSON member of the WebAuthn response, and this is what the back end must validate. More on this and other back end requirements in the next section…
how it works - back-end requirements
Whether you have a home-grown back end or a commercial solution for verifying passkey responses, there are a few new requirements you’ll need to make sure the back end meets.
Verify all origins
As I mentioned above, the origin sent to the back end (in clientDataJSON) will always be the actual web origin and not the RPID passed, whether for create() or get(). So if for example you had a common back end evaluating all responses, it would have to know about any and all related origins.
User database
In addition to checking the various origins, your back end verification services need to have a common understanding of user data, whether this by via sync fabric, a common user database or user validation API, or another solution. This would be true in any scenario in which separate services create and use common credentials, not just passkeys.
RPID context for users
Also as I called out above, you must ensure the RPID parameter is sent properly in WebAuthn create() and get() calls when it is needed.
For scenarios like I described above where there is one “home” domain associated with all passkeys, RPs could use one standard RPID (the domain where the metadata is hosted) and just send it for all create() and get() calls.
An alternative to this would be for create() calls to use the default web origin of the app where the passkey is being created. This requires a “full mesh” of related origins metadata posted at each possible domain, as is described in the passkeys.dev writeup. In this solution, the RPID is made part of the stored credential in the user database so that the correct RPID can be retrieved and used for get() calls in a username based flow, though it’s unclear how this would work for a username-less flow. Because the writeup comes from the FIDO team I take their recommendation seriously.
It seems like the common RPID approach or the “full mesh” approach can work well, depending on your environment. I leave it up to the reader to evaluate both.
conclusion
By default, passkeys can be enrolled and used across multiple domains that share a common, registrable domain suffix.
In order to use passkeys across disparate domains that do not share a common suffix, your options are to use federation (for example, OAuth / OpenID Connect token protocols) or to deploy related origins as specified in the latest WebAuthn protocol specification. For more information about it, check out the write-up at passkeys.dev.
In a multi-device passkey world, what can we know about a key?
Attestation, TOFU, and Provenance
Attestation, TOFU, and Provenance
intro
Here’s a code block:
let Sig = attestationObject.attStmt.sig; let certInfo = attestationObject.attStmt.certInfo; objVerify.update(certInfo); let answer = objVerify.verify(objKeyInfo, Sig);
Feel smarter yet? What do we know? What is the answer?
what does authentication mean?
We’re told that authentication verifies “you are who you say you are” (as opposed to authorization that governs what you’re able to do). But authentication really verifies that you have certain credentials a particular app or website has seen before. Any translation of credentials into a person or identity is the result of a separate task not generally done on authentication – it’s done before, when the credential is created and enrolled.
multiple-choice question
Proof of possession of a key means very little unless you know something about the key
As a developer, when you receive a signed assertion, you might wonder about the status of the key used for the signature. Has it been compromised or disclosed? Is it strong and resistant to common attacks? Who are you actually communicating with?
what is attestation?
The WebAuthn spec says that “attestation is a statement serving to bear witness, confirm, or authenticate“ and that "attestation is employed to attest to the provenance of an authenticator and the data it emits” (the latter including credential key pairs and other data).
Attest means to affirm to be true or genuine. But what is provenance?.

a quick aside: the definition of provenance
For this conversation we’re going to learn a new word: provenance. Its etymology is Latin via French, or perhaps some Greek, with prefix “pro” meaning “before” (give or take), and root “venir” meaning “to come”.
So…“to come before”?
Give or take.
In its first sense, provenance is a more grandiose way of saying “source or origin”.
In its second sense, provenance means “the history of ownership of a valued object or work of art or literature”, a chain of custody for the art world.
attestation defined
So now we have it. For WebAuthn, attestation can be defined as a statement that affirms to be true or genuine the source, origin, and/or chain of custody of an authenticator and the data it emits.
It seems like a tall order. How can we know the life story of a key and therefore how to think about its assertions?
Webauthn attestation can provide the relying party with verifiable evidence as to the environment in which the credential was created and certain aspects of the credential itself including the key pair. This evidence is an attestation object, the signature within, and optionally additional metadata. It also provides a way to assert a trust level on that information via the attestation signing key and signature.
webauthn attestation in reality
There are a ton of details to WebAuthn attestation. The specs variously cover attestation type, format, conveyance preferences, attestation services implemented by various vendors, and the FIDO metadata service. A lot of that stuff still seems in flight, but here are some things to know:
WebAuthn attestation is PKI. Most if not every attestation I’ve seen involves an attestation statement signed by either the credential private key itself or a special attestation key. Learning how to validate this signature will help you on your attestation journey
Attestation is much more clearly defined for hardware based keys (security keys and platform / TPM keys) than software keys or multi-device keys. There’s an established model for attestation formats like “packed” and “TPM”, along with FIDO metadata statement lookup based on the authenticator make and model's identifier or "AAGUID". For software / app based and multi-device keys, things are still evolving.
This blog post will illustrate some real world attestation examples I’ve observed, and keep it as simple as possible. If interested please read on.
So like I said above, attestation statement parsing can seem like a high complexity and low payoff activity. You have to:
choose which attestation conveyance (none, indirect/direct, enterprise) to request
understand and implement the verification procedure(s) for the attestation format(s) you support (none/packed/tpm/etc)
parse X509 certificates out of the attestation object
figure out algorithms and verify signatures and chains
verify the rest of the metadata from the authData and/or FIDO metadata statements, per the attestation format's verification procedure
All of this before you get to the part where you can actually decode cose to get the WebAuthn credential key out of a response and save it, to complete the registration.
So why do it? What does it get you?
The best answer I can give to this question is to think of it as analogous to verifying the server half of SSL/TLS. The part where you verify the server SSL certificate. That website may still be dodgy, but you’re reasonably sure it’s not fraudulent and dodgy.
a couple of real world examples
Windows Hello: attestation format ‘tpm’
Let’s take a look at registering a Windows Hello FIDO2 credential.
In this example we specify an attestation conveyance preference of ‘direct’, and we get back an attestation object with format ‘tpm’.
To find the attestation signature, we will look into the attStmt property of the attestationObject from the AuthenticatorResponse:

Attestation object showing the fmt, attStmt, and authData properties
Within this property is an object with several members, one of which is alg:

Attestation statement properties, showing the COSE algorithm identifier for RSA with SHA1
The alg property contains the identifier of the attestation signature algorithm. Not to be confused with the credential’s algorithm, this is the algorithm of the attestation signing key, and the accompanying hash algorithm used to create the attestation signature we’ll be checking.
If we check the IANA COSEAlgorithmIdentifier list, we see that -65535 indicates “RSASSA-PKCS1-v1_5 using SHA-1”.
Note: I’m not going to cover why Windows is using SHA-1 here, as it seems to be a complicated story and would probably merit its own blog post. In short they shouldn’t be, and they probably have reasons involving legacy code and hardware compliance. Maybe I will cover that in the future. Here, I’ll simply illustrate that the algorithm affects the JavaScript code you need to use to check the signature.
Here are the relevant code snippets for checking the sha1 signature of the TPM attestation statement:

Example javascript code snippets to parse attestation object of fmt ‘tpm’
Note that the certInfo structure is a TPM specific thing as specified in webauthn and the referenced TPM document.
The above only covers the bare minimum: checking the signature itself. For more information about validating a TPM attestation statement, check out the webauthn spec section (see “Verification Procedure”) and/or this blog article.
Yubikey 5 NFC: attestation format ‘packed’
Now let’s look at a different example. This one is a security key that uses the attestation format ‘packed’.
For this authenticator and attestation type, we get the following attestation object:

Attestation statement properties, showing the COSE algorithm identifier for ECDSA with SHA256
As we can see the alg now is -7. That maps to “ECDSA w/ SHA-256”. Good job Yubico 😊. So now we parse out the various pieces for signature verification as follows. Note that, for the ‘packed’ format, the signature is over the binary representation of the authData property, concatenated with the hash of the string representation of the clientDataJSON element of the AuthenticatorResponse.
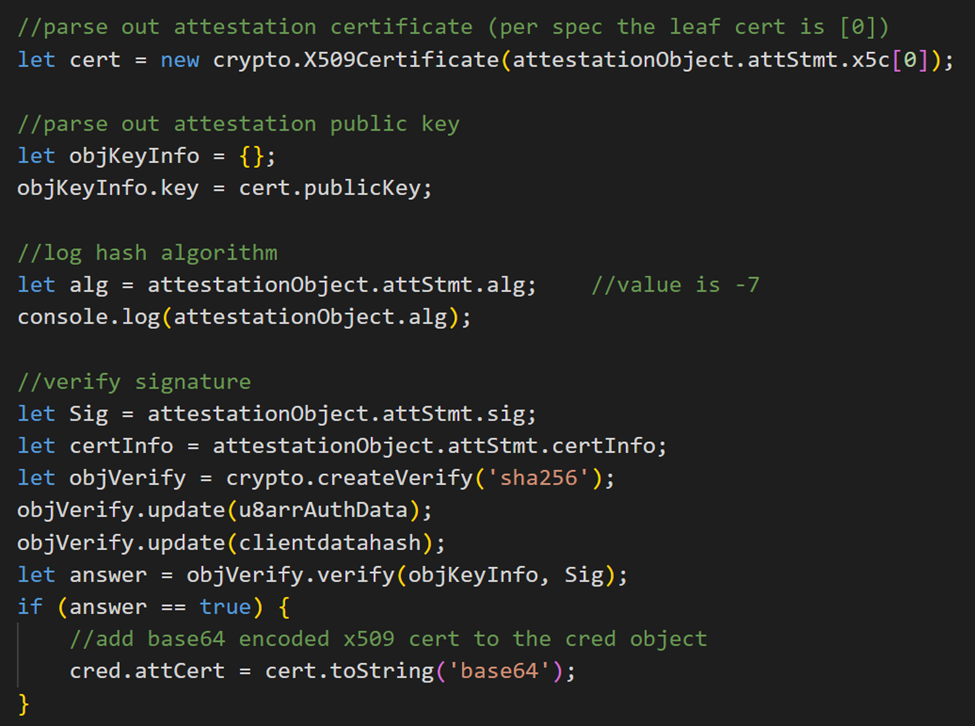
Example javascript code snippets to parse attestation object of fmt ‘packed’
attestation format ‘none’
For attestation objects with fmt “none”, the attStmt will be an empty object. This may mean the RP did not request attestation, the authenticator cannot provide it, or otherwise “none” can be an indicator of a multi-device credential (as we saw in a previous post).
a hopefully-helpful table
I know I said I’d keep it simple and wouldn’t go into minutae of attestation, but before we move on, in the spirit of a map that shows the complexity of the terrain yet helps illuminate a way through it, I offer the following table. My intent is to illustrate, conceptually, some key attestation “types” and what that means about where to find the key to check the signature against:
| Attestation type | RP request attestation conveyance preference | Resulting attestation statement fmt | Where to find the public key to check the signature |
|---|---|---|---|
| no attestation | “none” | “none” | Nowhere – there is no attestation statement therefore no attestation signature to check |
| self attestation | this seems to be the choice of the authenticator and not the RP | depends on the authenticator | Use the credential’s public key out of the attestation object’s authData property: attestationObject.authData.slice(55 + credentialIdLength); |
| all other attestation types | “indirect”, “direct”, or “enterprise” | not equal to “none” | Use the attestation key out of the first certificate located in the attestation object’s attStmt.x5c property: attestationObject.attStmt.x5c[0] |
The above was time consuming, and all we did was verify a signature. If you made it this far, bravo!
Now let’s look more comprehensively at what we might want to know, ask or query about a credential.
what do we want to know about a credential?
Once an authentication key is created and enrolled, there are a bunch of things that could influence the veracity of future authentications. If we’re going to ask for info about a cred or key, what makes sense to ask about and what can we actually know?
What attestation covers
As we’ve seen above, there are aspects of key origin and provenance that can be gleaned well from WebAuthn authenticator attestation responses, at least for hardware keys.
key type
Was the credential key an RSA key, an ECC/ECDSA key, or something else? Does it use the current recommended key lengths? What about the attestation key and chain? The attestation response itself contains this information.
where the (hardware) key was generated
What type of environment was the key was generated in? Was it a physical security key, a computer, or a mobile device? Was the key created in a secure hardware element? In software? For hardware keys, the attestation statement provides this information via signed object and metadata.
what attestation misses
I’ve shown above how attestation creates evidence of what type of device a key was generated on, especially if that device was specialized hardware such as a security key, TPM, or platform secure element. Beyond this, there are variables that significantly affect key / authentication trust but that are not covered by attestation.
conditions of enrollment (and/or recovery)
As I mentioned in the factors we choose, not all sign in factors are equal, and that applies to enrollment factors as well. So it makes sense to ask what were the type(s) of factor(s) and evidence required as a condition of enrollment or to recover a lost key. Was the key created and enrolled with no evidence (aka “trust on first use” or TOFU) or with additional evidence factors such as previous credentials or identity documents?
environment for software keys
While attestation objects and statements can specify well defined and understood hardware environments, keys created and maintained in software, such as in a browser or in an app, are subject to many more variable environmental factors, Things that vary across time include: Is the device platform and software up to date with security updates? Has it been jailbroken? What type(s) of application(s) are running? What type(s) of endpoint protection tools? There is a seemingly endless list of questions to ask to assess software environment safety and trust.
what has happened since enrollment
Passkeys are copy-able, and once a key is copied to a different device, promises made on the original attestation / provenance statement are void.
So another good question is what may or may not have happened to the key since enrollment? Is the key exportable from its platform? Is it part of an ecosystem that will copy it? Was it indeed exported or copied? Where is the credential information stored and maintained? Is it in a database, file, or public key certificate chain, and how is it protected? What is the access control and/or data protection? Has there been a relevant data breach of either private key information or public key to identity mapping?
attestation alternative: TOFU + continuous risk assessment
Trust is built over time. As a person or entity’s behavior is observed, patterns emerge that become increasingly intricate with more data, and risk assessments based on this behavior improve. In this way, the credentials accrete value with continued successful use.
Continuous risk assessment over the session has become a basic requirement for modern authentication. This principle applies to the credential lifecycle as well.
As an alternative or complement to WebAuthn attestation, continuous risk based assessment that looks at credential status w/r/t the questions above, on attested or un-attested keys, can provide good ongoing assurance of credential trust.
what’s next
there will be even more keys
One result of risk concerns about copyable keys will be: you guessed it, more keys.
The device public key or DPK protocol extension is in draft mode and specifies that a multi device WebAuthn credential can be supplemented with one or more device specific credentials upon request by the relying party. The device keys cannot be used on their own. They provide additional risk mitigation information, as assertions signed by the device keys will supplement normal webauthn signed assertions via an extension to the protocol. The new keys can be enrolled based on possession of a user-level key, or can require more factors. This is up to the relying party.
more keys -> more attestation
The enrollment of more keys invites of course more attestation. DPK keys are device specific, which makes them somewhat of a natural fit for attestation. Within the DPK extension “attestation on device key enrollment” can provide attestation information about the device key itself.
Separately and also in draft mode is a generic ability to request attestation on WebAuthn get() calls rather than just on Create(). This is irrespective of DPK extension use and will provide another source of ongoing / continuous risk signals for sign on.
attestation adoption will follow the pattern of PKI
I expect that DoD’s and other government agencies will implement/deploy WebAuthn’s attestation specifications fully, though it will take some time. I’d guess that other / regulated industries such as banks and healthcare organizations will do a combination: support the minimum (perhaps signature validation only and/or FIDO metadata existence check) but combine attestation with their own industry specific validation tools and algorithms. Other organizations and relying parties will either support the minimum or ignore attestation entirely (send conveyance preference ‘none’) and replace any attestation information with a policy of TOFU combined with a risk assessment engine they can query dynamically.
TOFU models combined with continuous risk assessment
Trust-on-first-use and multi-device keys (often in software) adopted for consumer scenarios and less regulated industries will enable their customers to enjoy the relative ease of use of these keys.
The WebAuthn attestation approach is heavy handed for these scenarios. A better and cheaper way will be for relying parties to focus energies on the ongoing health of their users’ sign on context. My hope is that sign on risk assessment APIs and services that already exist will continue to evolve and remain open to third parties. I don’t know much about these services yet (as perhaps evidenced by the quality of those links), but I look forward to learning. If they do it well, this ecosystem can enable credential risk to become part of the authentication context while protecting anonymity and privacy.
conclusion
WebAuthn’s attestation model is a complex beast. The essentials of it are useful for developers and relying parties to know about. The rest will be good for governments and similar organizations. There are many relevant questions about key trust that cannot be answered by attestation, either because the keys are in software, the questions require more context, or both. Continuous risk assessment APIs and services will be more helpful for these questions.
How it started, how it’s going
My journey (so far) with JavaScript
My journey (so far) with JavaScript
At the beginning if this year I decided to learn JavaScript beyond just the “PM level,” which in my world means you know form.submit and navigator.credentials.get and the rest you fake.
The truth is, I’ve always liked building things. Myself. With my own hands (or keyboard). This unfortunately is something my PM career has caused me to put on the back burner much of the time. Beyond demo’s for events and sample apps for documentation, my work life tends to consist of encouraging others to build things, rather than building them myself.
I’d like to change that.
So I decided to start. And I picked JavaScript to start with for two reasons: one, it’s everywhere. It’s in the browser, it’s on the server, it’s in native and mobile apps via components like SFSafariViewController and frameworks like React. And two, it is the first use case for the WebAuthn protocol, which makes it highly relevant to the cause of good sign in.
I won’t bore myself writing everything I learned, but for fun here are a few random JavaScript learnings:
we play fast and loose with types here. but it’s a good idea to specify [] or {} for array or object declaration, respectively
an empty array ([]) is not falsey (an empty array’s array.length is though)
strings are UTF16, so characters are stored as single double-byte surrogate or surrogate pair (4 bytes total). this is abstracted away inside codepointat() so it can be hard to tell what’s going on.
i haven’t found something like “memory view” in Visual Studio Code or browser debuggers unless the variable is a buffer or array – this was very limiting when trying to figure out the item above 😠.
if the client js file is a module (which it is if it has an “import” statement at top), then the script element in html needs the attribute type=“module”, or it will not find the javascript and nothing will work
Anyway bottom line, here’s where we are currently: visit Fun with WebAuthn.
You’ll need to wait a minute (I’m still not paying for the always on feature).
Ok, maybe I’ll illustrate…
At the beginning I wrote a spec of sorts, outlining 7 requirements the “identity project” would need to meet. At this point I’ve met almost all. Requirement 6 ultimately became this blog. And current WebAuthn options (requirement 4) ended up being more about conditional mediation than credential management. I ended up cutting requirement 7 (React) as it was not a requirement, and it didn’t end up being necessary to meet the others.

My initial “spec” for the “Identity Project”
Then, I got to work building. The day I met the ubiquitous “hello world” milestone was memorable even if it seems underwhelming now:

Hello, world.
Weeks and months of iterative progress later, I have something very close to what I envisioned originally, if not spot on. There’s always more work to do, and it’s not bug free, but it exists and it works. (Also it has five color schemes, my favorite depicted below).

Today
What’s next? There’s a bug with Safari on my iPhone, so I’ll be looking into that.
These are not edge cases…
Listening to a FIDO UX podcast, wanted to get this down while I’m thinking about it.
Listening to a FIDO UX podcast, wanted to get this down while I’m thinking about it.
Here is a list of sign on experiences that definitely are _not_ edge cases. Some are literally the first thing users do, others are the first thing customers ask about (in my experience). In no particular order:
New phone – pairing* / first use
Additional phone – pairing / first use
New computer/laptop – pairing / first use
Temporary device – such as in cases where phones are not allowed or phone has been forgotten
No access to phone / no phone at all
* RE pairing – this can refer to a few different things depending on the key / credential model, including pairing of a phone with a laptop for future use as a remote authenticator, or enrolling a platform authenticator (such as on a laptop) based on possession of the remote authenticator (such as on the phone)
Let’s all get [more] familiar with password autofill
We’ll be seeing (and using) a lot more of it with passkeys.
We’ll be seeing (and using) a lot more of it with passkeys.
contents
Password managers, browsers and autofill
background
The inspiration for this article came from a simple and straightforward question/comment I received last week over email:
“this whole password and where to save them thing is driving me wacky. If Google saves all my passwords what does that mean”
I became inspired to write an article that would be consumable by most people and that would tie their struggles with passwords to the importance of using password managers today and, in the future, to the opportunities to use passkeys with password managers as well.
It didn’t go as expected.
I expected to sub-title this article How I stopped worrying and learned to love password managers. Then, I spent a few days getting more familiar with using password managers the way they were intended – as tools to automatically enter usernames and passwords via browsers and apps. This is different from how I have historically used my own password manager, which is more like a security deposit box in which I will periodically enter the long and complicated password manager password, copy one password out of the vault and use it.
After working with, and trying to work with, the more common use case scenarios I can say one thing: You guys, I’m a little worried. (jump straight to why I’m worried).
password managers, browsers, and autofill
Most browsers (Chrome, Safari, Edge etc) have basic capabilities of password management: to generate, save, and populate passwords into web forms and apps. In addition to browsers there are separate password manager products such as 1Password or LastPass that provide similar functionality, with browser plugins to enable you to use them for password saving, autofill and autocomplete. In this article, I’m not going to express an opinion as to which is better.
Chrome browser prompt to save password

Chrome browser password autofill menu on amazon.com site

Simple username and password autofill in Safari on iPhone
what is autofill
Autofill and the related term autocomplete refer to the capability of web browsers and some apps to remember data you enter and, when you visit next time, either pre-populate it or provide menu options to help you re-enter the same information without having to type it in again. It is commonly used for usernames and passwords, as well as things like address data and payment information.
how it works
Most browsers (Chrome, Safari, Edge etc) have settings and options to control whether username and password saving, autofill and autocomplete are done, and if so, where the usernames and passwords can be stored and therefore used. For example, with Chrome you can choose to save them only on the local computer, or otherwise in your Google cloud account so that they can be used on any computer where you have signed in to the browser with that account.
On input fields in web pages, browsers and password manager browser plugins use HTML attributes like autocomplete and name to determine whether to prompt to save username / password combinations.
Upon a successful sign in, the browser or plug-in will prompt the user to save the password (see Chrome image above). On subsequent visits to same site, if not already logged in, the browser or plugin will prompt the user to use a saved username/password combination. If the user does not want to use the default suggestion, they can click the key symbol (lower right) and get additional options:

Safari on iPhone prompt to use a saved username and password

Safari on iPhone other password options
Native mobile apps support the same patterns via platform support for browser saved passwords as well as things like iCloud Keychain.
what does this have to do with passkeys
As I teased in my last post, major vendors are planning to include passkeys as first class citizens alongside passwords in autocomplete scenarios. The concept is called “conditional mediation” and it just means that the user experience for selecting and using passkeys should not be as jarring as it currently is. For example, below is how my webauthn sample app looks in Safari on the iPhone (once I added conditional mediation support):

WebAuthn sample app with conditional mediation support in Safari on iPhone
Note that the passkey credential the phone is prompting me for is a passkey I had created on my Mac and sync’d to iCloud via the keychain.
Given this it would seem to make perfect sense for the other password managers to start supporting passkeys ASAP.
why I'm worried
While browsers and password managers can enable relatively easy password entry experiences, you must have achieved the following for them to succeed:
Install a password manager or otherwise choose a browser in which passwords will be stored
If using a password manager, install browser plugins for that password manager on every browser you use, on every device (computer and phone). Otherwise, configure the built-in browser’s password management settings correctly.
If using a browser’s built in password management, determine whether to store passwords only locally (i.e. on one computer) or in a cloud account (such as Google or Apple) that will then sync the passwords to other devices, and ensure you have the sync settings correctly configured on the account.
Ensure you populate the browser or password manager correctly for each password – the website, username, and password must match.
If, upon a successful login, you accept the password manager’s prompts properly, the above can happen automatically. However, the variety of user experiences across devices, browsers and sites are not exactly straightforward. This is not to mention that most passwords people wish to use are passwords they have already created, which means importing (if possible) or confidently recalling and manually re-keying the password into the password manager will be required.
Finally, I can’t see that any of the above concerns will be resolved with passkeys, as the user experience and the tools required will, by design and the current industry plan of record, be the same as for passwords. UPDATE: Ok, that last sentence was a bit too pessimistic. Passkey support at the platform level across Apple, Android and Microsoft will ease the installation and configuration challenges, and of course passkeys don’t have the challenge of re-keying the password itself. Here is a little more rational of a list of the key management challenges we will have with passkeys in password managers (adapted from my earlier article A Bazillion Keys):
I have passkeys across various cloud accounts on my computers and phones. How can these passkeys be kept track of?
Oh shoot, which passkey did I use for this site and which account, phone or computer does it live on?
Do I have a backup passkey for this site?
What if I need to revoke or invalidate a passkey?
I have a new phone and want to make sure my passkeys from all my accounts are there. How can I do this easily?
What if I lose my phone, which has a lot of passkeys on it?
Bottom line, there will be plenty of work for us to do creating good key management and use experiences!
FAQ for users
With all of that said, I went ahead and created some user facing words that may help address the question of “what does it mean” to store passwords. I’ve included it here because the content does not yet merit it’s own article with a non “identity-nerd” tag :(.
If Google saves all my passwords what does that mean?
In short it means that your usernames and passwords will be saved with your Google account and can therefore be used in the future without having to type them in.
A few more details…
Most web browsers (Chrome, Safari, Edge etc) have the capability to remember data you enter and, when you visit a site the next time, either pre-populate it or provide menu options to help you re-enter the same information without having to type it in again. This capability is commonly used for usernames and passwords, but it’s also used for things like address data and payment information.
Browsers will have settings and options to control these capabilities including where the usernames and passwords are stored and can be used. For example, with the Chrome browser you can choose to save them only on the local computer, or otherwise in your Google cloud account so that they can be used on any computer where you have signed into that account. For example, here are the Chrome prompts to save password with local and Google options selected, respectively:

Save password locally in Google password manager

Save to Google account
In addition to browsers, there are separate password manager products such as 1Password or LastPass that provide similar functionality and work with most browsers, but provide their own username and password storage location, separate from your Apple, Google, or other cloud accounts.
Some of your mobile phone apps will also be able to auto-save passwords and/or to consume saved passwords from a browser or password manager, but these capabilities are going to be hit or miss.
Why use one of these password managers to store passwords?
To answer the question of “why store passwords,” we have to back up a bit. Of course, storing passwords changes the way you enter those passwords. It can seem more difficult at first because you have to interact with the password manager, select the correct password, and of course deal with any unexpected aspects of the experience (such as an incompatibility between the site and the password manager). This imposes both cost and risk (of not being able to sign in easily) on you.
The answer to this question comes down to security. Using a password manager, whether a third party one or one built into your favorite browser, enables you to use stronger passwords and to use specific passwords for each site.
Huh?
Password managers not only store and auto-fill passwords, they have the capability to generate them as well. They do a much better job than us humans at generating passwords that are random enough to be safe. If we select our own passwords, we’re much more likely to use predictable, non-random passwords, not to mention use the same passwords with multiple sites, making us more vulnerable to password compromise. The password manager generated passwords put us in a much more secure place.
These safer passwords are much harder for a human to remember, but password manager capabilities to store and auto-populate passwords make this easier.
So to sum up, between better password generation and easier password storage and use, password managers make having safer passwords for each app or website actually feasible. That’s why you should use them.
Protecting the password manager itself
You will of course need to protect the password manager itself with a strong password and additional factors. Different types of password managers will have different approaches to help you do this.
Browser based password managers will tend to depend on your computer or phone password, PIN and/or biometric for protection
If syncing to a cloud account, ensure the cloud account (such as your Google account) is secured with multi factor authentication in addition to a password.
For third party password managers, the password manager itself will provide ways to have multi factor authentication such as device specific passwords, phone apps or text messages, and/or integration with the device password or PIN
In any case, ensure you have a backup of your password manager credentials, even if it is a written down physical backup that you keep in your closet or desk drawer (yep, you read that correctly).
Bottom line
Using a password manager, you can make sure your password for each site is different and reasonably unpredictable. The security benefit of this exceeds any increased risk due to syncing passwords or storing them (provided you protect the password manager itself with a strong password and multi factor authentication).
You should not just believe me on this. Please take a look at renowned security expert Roger Grimes’ blog entry at KnowBe4: https://blog.knowbe4.com/what-about-password-manager-risks
What does CABLE have to do with passkeys?
This is my third post about passkeys, and with all that’s going on it looks like there will be a few more after this.
This is my third post about passkeys, and with all that’s going on it looks like there will be a few more after this.
to recap
Previously in this blog series, I covered the industry’s broad announcements about passkey support, noting that it would be a positive development to overcome the most significant objection to FIDO2 credentials: the lack of an account recovery story.
My second passkey post followed up with information from Yubico that clarified terminology and placed passkeys in context as a good consumer solution, but one that would likely not meet the needs of enterprises who require more assurance of credential attestation and ongoing risk assthe-new-fido-essment/mitigation.
On that terminology question, in case you need a reminder:
Industry term: passkeys
FIDO Alliance term: multi-device FIDO credentials (as opposed to single device credentials)
Yubico term: copyable passkeys (as opposed to hardware-bound passkeys)
silos of credentials
Once the account recovery story is solved (for consumer scenarios, anyway) by passkeys backed up to Apple, Google, Microsoft etc, the next objection becomes: what do we do about these silos of credentials? Am I going to need to worry about having separate credentials for each website or app, based on whether I access them from my Apple iPhone, iPad or Mac, Android phone, or Windows laptop?
The answer comes in a detail from the initial announcements: that FIDO authenticators will be able to connect over Bluetooth / BLE to the computer from which the user is accessing resources.
Cloud Assisted BLE
While USB and NFC are widely used by security keys, Bluetooth as a transport for FIDO2 credential registration and use seems targeted at the wide variety of scenarios in which the authenticator is a mobile phone.
While BLE was already one of the transports specified in CTAP (one of the FIDO specifications), there were apparently some pieces missing. In particular, the unreliability of Bluetooth pairing and the quality of the connection made it a very difficult transport for authentication. A new scheme for inline BLE pairing and secure communication was needed.
This new protocol is called “cloud assisted Bluetooth LE” or “caBLE”. While at the moment public information is scarce, the FIDO Alliance makes it clear that “an upcoming version of CTAP” will specify this usage (possibly CTAP version 2.2, though don’t quote me).
Meanwhile, industry support is not awaiting the public document. Today, both Android phones and iPhones are able to enroll and use FIDO credentials over Bluetooth.
Why does this Bluetooth thing matter
This is important because, while passkeys provide account recovery without reverting to phishable factors, the remaining concern is that ecosystems of credentials – Apple, Google, Microsoft – will not play nicely with one another (read: sync). In that case users will be left to maintain separate islands of credentials: iCloud keychain, Microsoft Authenticator, Google Smart Lock app.
This is why the Bluetooth thing matters. What caBLE enables is for you to use a phone from one ecosystem (iPhone or Android) to sign in on an unknown Windows PC, for example, to any resource that supports WebAuthn. This means you won’t be stuck in separate silos. Any resource (app or website) that supports Webauthn will be able to accept credentials over caBLE as easily as they do local platform credentials from the MacOS or PC, or credentials from a security key attached via USB or NFC.
Example: Enroll and use a passkey (WebAuthn credential) on my iPhone from a Windows PC
setup
For this example, i use my own iPhone running iOS 15.6.1 in developer mode (to enable the passkey preview via developer settings):

On my Surface Laptop running Windows 10, this example uses Chrome version 104.0.5112.102
steps
First, open Chrome and navigate to your favorite WebAuthn supporting site. Choose to register. Chrome will present options, of which “Add a new phone” should be one (note: In canary versions of Chrome the UI string becomes “Use phone with a QR code”):
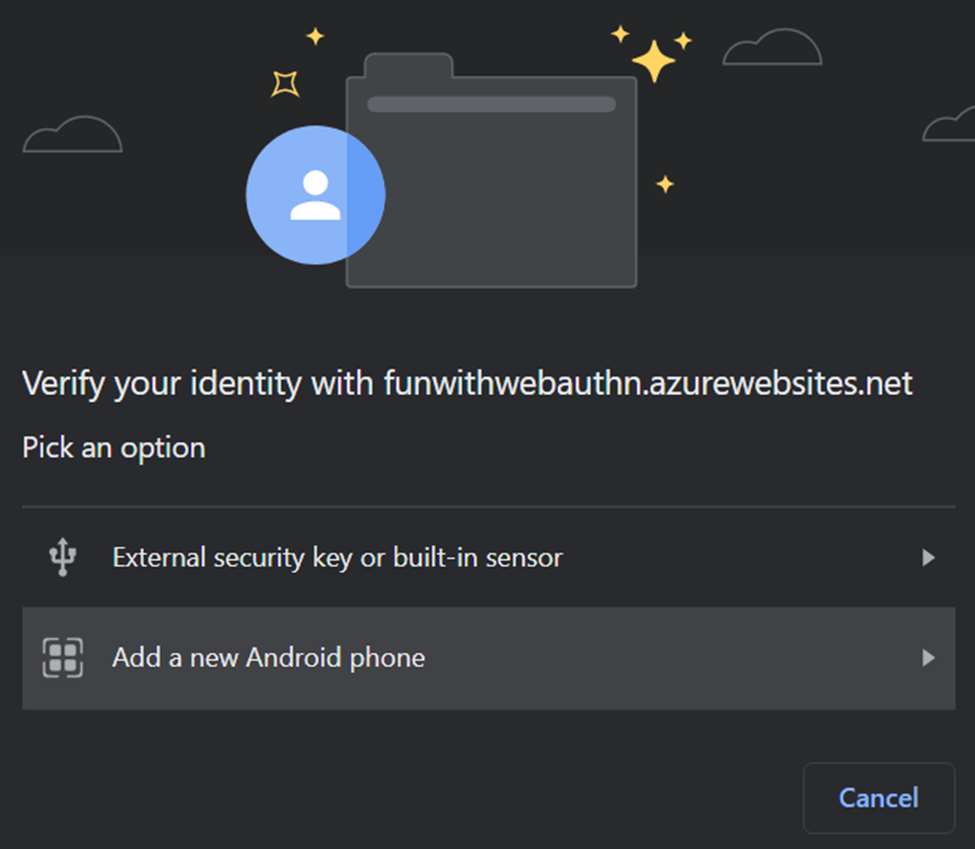
Select “add a new android phone”:

Open your iPhone’s Camera app, point at the screen and capture the QR code:

Select “Sign in with a passkey” on the phone screen:

Press “Continue” to confirm creating a new passkey on the iPhone.
Upon re-visiting the WebAuthn relying party, sign in the same way (by selecting “add a new android phone” or similar in the browser).

Press “continue” to confirm signin with your iPhone resident passkey.
Additional notes
Transport hint
Once registration over BLE is complete and you have the response back from navigator.credentials.create(), the “getTransports()” call returns an array containing a single entry “cable”:

Attestation statement format
In each test observed, the attestation format (attestationObject.fmt) of the new credential was “none”. It is not clear currently if this will be the definitional attestation format for passkeys, or if there will be others
Behind the scenes
For a few more details about what the underlying protocol for QR code and pairing, take a look at time code 28:25 here

What’s next
This example was super-basic – what will improve the UX hopefully this year:
“Conditional mediation” including auto-complete support in browsers as well as native apps promises to promote WebAuthn credentials / passkeys to first class citizens alongside passwords saved in browsers, password managers, and iCloud keychain.
Using the above and other advancements, in the near future native apps should be able to offer more refined user experiences for caBLE as well as local registration and auth using WebAuthn credentials / passkeys
In particular, using caBLE to enroll a local credential on a laptop (that you plan to use again) will enable easy credential portability across Apple, Google, and Microsoft universes, combined with a much easier local login experience ongoing.
Look for upcoming posts to cover related passkey topics:
What will attestation mean in a world of passkeys? Will passkeys offer only attestation format “none” or will other attestation types for copyable passkeys come into utilization?
Already in draft, the “DPK” protocol will enable copyable / multi-device passkeys to be supplemented by device specific, single device keys to strengthen authentication assurance. Enrolling these new keys on a new device requires it’s own attestation model and pre-requisite factors. Use of these device specific keys will require new patterns as well.
What does the “conditional mediation” user experience buy us? Where is it supported?
New protocol flags to indicate multi-device status: BE (backup eligible) and BS (backup status) are currently being written into the protocol specs. I have not yet been able to observe these in the authData flags member coming back from create() or get() (the former is where I’ve read it should be) – more on this once I have more info.
More about passkeys
Following up on my previous post on FIDO announcements, I have some new info from this morning’s Yubico webinar entitled Passkeys and the future of modern authentication: Q&A with Yubico’s CTO. Here are my takeaways
Following up on my previous post on FIDO announcements, I have some new info from this morning’s Yubico webinar entitled Passkeys and the future of modern authentication: Q&A with Yubico’s CTO. Here are my takeaways in case you don’t have time to watch the video.
Terminology
First, Yubico defined their take on the new term.
Noting that it was first mentioned “to a wide audience” by Apple at WWDC 2021 as a technology preview, and then announced at this year’s WWDC as broadly available in iOS 16 and MacOS Ventura, they defined a “passkey” as a “passwordless-enabled FIDO credential”.
Bottom line: the passkey can replace a password, and is more secure due to public-key cryptography.
Specifically, to refer to what the FIDO Alliance calls multi-device FIDO credentials, Yubico will use the terminology “copyable passkeys”. This refers to passkeys (FIDO credentials) that have been and/or can be copied to multiple devices such as mobile phones and laptops (for example, what Apple is doing via the iCloud keychain).
Yubico also points out that there is a different flavor of passkey they will call “hardware bound passkeys”. This refers specifically to passkeys (FIDO credentials) that cannot and have not been copied anywhere beyond the authenticator device (for example a security key or Yubikey) where they were created.
The gist of the presentation was that copyable passkeys will be a good fit for consumer scenarios, whereas enterprises will still require the benefits of hardware bound passkeys and their associated security and attestation.
Attestation
Next, Yubico offered a deep dive and pitch for attestation, the process by which information about a FIDO credential is passed to a relying party website upon creation. I won’t do it justice here, but in short there is a gradient of attestation strength, from literally “none” to a manufacturer-asserted and signed statement regarding the security of the authenticator key and device. Cloud providers such as Google can provide attestation based on an Android device sign in, whereas Yubico’s security keys provide attestation statements that come from the device via in-built capabilities from the authenticator manufacturer itself.
Bottom line: attestation today is relatively clear for hardware bound passkeys, but it is still being figured out for the copyable or multi-device passkeys. We should stay tuned.
Futures
One intriguing statement from Yubico’s CTO towards the end of the webinar was that in the future, attestation would not just occur at creation. I’m not sure if it means attestation will move into the the authentication flows as well, or what, and I wonder to what extent he’s talking about this. Time will tell.
Reference
For info from Yubico on passkeys, see their FAQ here.
Challenging times
Never sign a challenge from someone you don’t know
Never sign a challenge from someone you don’t know
This is the internet advice for the Webauthn/FIDO age.
Within Webauthn, the challenge is a data element that is newly generated by the relying party for each transaction, both create() and get(), with the goal that the value never repeats. And unlike a time-based one-time password (TOTP), the challenge value should not be predictable. This is generally achieved by using a sufficiently random function.
Why challenge?
Webauthn sign on is based on proof of possession of a private key. In order to prove possession, the authenticator creates a digital signature by applying the private key to some data. But not just any data. The authenticator must sign new data that has not been used in a previous transaction. The point is that if you have to sign a new value, you must actually possess the key. You cannot re-use an attestation or assertion signed previously and/or stolen from someone else. (The Webauthn signed data includes the challenge as well as relying party id and authenticator data). The relying party website can then verify that the signed challenge has not been used before and that it matches the challenge that was generated for the corresponding Webauthn request.
But, what a malicious actor could do is act as a man-in-the-middle (MITM), handing a challenge over to the real possessor of the key and trick them into signing it, right?
Well, hopefully that is not so easy in the Webauthn protocol, thanks to another anti-phishing, anti-MITM feature, the origin check. This means that the Webauthn authenticator will reject a request from a website that does not have a secure (HTTPS) web origin (https://www.example.org) that matches a relying party ID (RP ID) mapped to an existing credential on the authenticator. (For create() calls, the secure web origin is used to create the RP ID mapping to the new credential.)
So to recap:
Fraudsters trying to use stolen signed assertions will have a difficult task in that their stolen assertions will be rejected by the relying party website for failing the challenge match
Fraudsters trying to setup phishing sites to relay challenges and signed assertions back and forth between website and victim will have a difficult job as they will fail the Webauthn protocol’s origin check
Where to find the challenge
The challenge can be found within the clientDataJSON ArrayBuffer returned within the response member of the PublicKeyCredential returned from the WebAuthn API create() or get() call.
Takeaway
Let’s make sure your Webauthn implementation isn’t unnecessarily vulnerable in the area of Webauthn challenge / challenges.
If you are a relying party supporting Webauthn sign on, make sure you:
As described in the Webauthn spec, be sure to positively check the value of the challenge returned from every Webauthn create() and get(), in addition to checking the signature.
Don’t just compare the challenge to previously-redeemed challenge values. While this would mitigate replay attacks, a better security approach is to verify positively that the challenge value included and signed in the response is the exact challenge originally generated for that same credential create or get and included in the PublicKeyCredentialCreationOptions / PublicKeyCredentialRequestOptions object initially sent.
The above will require you to store transactional data / state so that matching can be done. This problem is not prescriptively addressed within the Webauthn/FIDO standard, so you will have to determine the approach that works best for you, for example taking into account request context information to ensure the client requesting the challenge is the same as the client redeeming the assertion.
Final note
The above will not protect your implementation if malicious code has been able to switch the challenge you generated for your client for one from a third party, but at least you will be resilient to unnecessary vulnerability to replay and phishing/MITM attacks.
About the new FIDO announcements…
This March and May brought several new announcements about the expansion of FIDO standards and of passwordless in general. The announcements came from Microsoft, Apple, and Google and followed announcements by Yubico earlier this spring and by Apple last year. It has even generated mainstream news coverage at several venues. So, what exactly was announced?
This March and May brought several new announcements about the expansion of FIDO standards and of passwordless in general.
The announcements came from Microsoft, Apple, and Google and followed announcements by Yubico earlier this spring and by Apple last year. It has even generated mainstream news coverage at several venues.
So, what exactly was announced, and how does it change what we’re doing today?
What are passkeys
First, the announcements re-introduced “passkeys”, this time as an industry term instead of an Apple specific one. Passkeys will refer to the new generation of Webauthn/FIDO credentials that can be backed up, including private keys, to another device, for example to the cloud. As a development, this is both trivial and non-trivial: trivial in that this is how basically all content is backed up today. Non-trivial in that it breaks the public/private key pair promise of “the private key doesn’t leave the device where it was generated”.
Re-capping from my previous article A Bazillion Keys, there are a couple of reasons my gut is that this is the right approach for the industry:
How to handle backups and account recovery has been one of the most significant blockers to broad adoption of Webauthn/FIDO credentials, and
Solutions offered so far, mainly enrollment of other factors, manual enrollment of backup keys (even if made a lot easier), and identity verification services are too cumbersome and inconvenient for broad adoption.
To the objection that private keys should not leave the device, the response is simple: that ship has already sailed! Windows Hello for Business, FIDO U2F, and FIDO2 have all embraced the pattern of encrypting and sending private keys from client to relying party and/or vice versa. In particular, FIDO U2F and FIDO2 “non discoverable” aka “non resident” key patterns require relying parties to store and manage the entire encrypted Public Key Credential Source, containing the private key, on behalf of the user.
With the new model of passkeys seamlessly backed up to the cloud, users of Webauthn/FIDO credentials will enjoy the same availability and portability that the leading authenticator apps offer today for OTP credentials, for example. When you get a new phone, they will just be there, and the experience for using them will be the same. This is what users expect, and anything more inconvenient than this they will not adopt.
What about FIDO is changing
While the above is the main headline, the announcements included a couple of statements of intent from the vendors and the FIDO standards community, respectively, to support two things:
Outside of the FIDO standards, major Webauthn/FIDO implementing identity providers from Microsoft, Apple, and Google will plan for and support scenarios in which credentials are passkeys that may therefore have been synced / backed up in multiple locations. Google’s announcement in particular positively states the intention that “Even if you lose your phone, your passkeys will securely sync to your new phone from cloud backup”.
Within FIDO standards, the FIDO Alliance announced upcoming support for:
Enhanced FIDO standards to address authenticator devices that use Bluetooth to connect to the computer or device from which the user is trying to authenticate. While this is basically an unrelated change, it fits within the broader theme of extending applicability and usability of Webauthn/FIDO credentials on mobile phones, which is welcome.
WebAuthn/FIDO extension(s) to enable relying parties to recognize whether a credential is a passkey, in other words whether that credential has the capability to exist on multiple devices, as well as to provide the ability to request/require the “old behavior” in which keys are bound to a single device.
When is this happening
Basically, all of the announcements were announcements of intent. There is not a launch date, nor even a clear timeline or ETA, for passkeys nor for the new FIDO options.
Given this, what should the industry do?
For relying parties, especially those with existing or planned Webauthn support, you should think about how your capabilities will deal with passkeys. Will you want to use the extension? Will you want to know whether credentials your users enroll will be passkeys or not? Consider making these preferences and requirements known to the FIDO standards community.
For identity providers, I’m sure most already know this, but plan your model for dealing with passkeys, specifically the capability to “back up” or “sync” credentials so that users will have seamless access to them when they lose devices, change devices, etc. According to the currently stated plan, this will not be a FIDO standard, so how you implement these capabilities is going to be up to you.
A bazillion keys
This is my favorite and most interesting “new” problem that is not new 😊.
This is my favorite and most interesting “new” problem that is not new 😊.
One of the defining characteristics of Webauthn is that it requires a distinct key pair for each resource and each client device. This provides the advantage of privacy that comes from non-correlation across sites, but it also multiplies the number of new keys we’ll be dealing with, exceeding even the number of passwords each of us has today.
A world of widespread Webauthn/FIDO2 deployment will be one of approximately “one bazillion” keys across platform and roaming authenticators, users, devices, and relying parties. This creates the potential for a key management nightmare.
And unlike the mixed bag of API keys, tokens, confidential client secrets, passwords, and you-name-it that can be managed by a Secrets Management solution, these new keys will be user keys vs machine-to-machine keys. So these keys will require user experiences not only for usage, but for other common tasks we will need to perform to be able to use our keys easily. The problems are a bit more than simple create, get, list, and delete on a given authenticator.
We will need solutions to common situations like:
Oh shoot, which key did I use for this site and which authenticator device does it live on?
Do I have a backup key? Is it up to date?
I have keys across authenticator devices, computers and phones. How can these keys be kept track of?
What if I need to revoke or invalidate a key?
I have a new phone and want to provision keys on the platform authenticator for a large number of accounts all at once. How can I do this easily?
What if I lose my phone, which has a lot of keys on it?
Before leaping to “the user shouldn’t have to know” and “we’ll do it all behind the scenes silently”, please recall from Principles of Good Auth, where I said that access control decisions need to be explicit because, amongst other things, the “friction” or trouble taken to interact with [our keys] has a good result – it trains us to make better choices.
So let’s talk about some concepts and patterns for implementers and enterprises to help us have the right credential and key management solutions for the world of a bazillion keys.
Optimizing Key Issuance
The first way to mitigate this proliferation of keys is to ensure keys are enrolled in an efficient way so that we don’t have more keys than we need, but we have sufficient keys to cover the access scenarios. This is of course in the control of the websites / relying parties who support key-based sign in. Here are a few things they should think about:
Platform vs roaming authenticators. A platform authenticator – on the user’s phone or laptop – is going to be the most convenient to use for day to day sign on. A user will likely enroll more than one of these. A roaming / “cross platform” authenticator (a.k.a. a security key) can connect to a laptop, phone or other device, providing multi device support as well as a backup key.
Use of identity providers as aggregators. There are two ways for a relying party to support Webauthn sign in: either natively, consuming and validating Webauthn assertions, or via federated single sign on from identity providers (IDP) who support Webauthn. In the latter case, the website simply needs to support the federated authentication method – SAML, OAuth, etc – that the identity provider supports. How should websites and apps decide which approach to use? To answer this question you must consider the weight with which your app or service values privacy / anonymity of users vs the efficiency of simply pointing to an IDP. Also, what is the cost of implementing Webauthn natively, and taking on the management of all of your users’ credentials, vs outsourcing that task to an IDP?
Use of resident/discoverable keys. While the choice of resident or non resident keys doesn’t affect key proliferation (the keys still exist no matter where they are stored), this implementation choice does affect key management scenarios, mostly because taking on storage/protection of a private key shifts a management burden from the user to the relying party, both in terms of allocating capacity to manage the keys and in terms of protecting private information.
Implementation: Key and Credential Management Experiences
So, which key management scenarios and capabilities are most important? This is of course up to the implementers, but here are some thoughts from me about which are the most imperative:
For Webauthn supporting websites / relying parties
Enable enrollment of multiple factors, including of multiple Webauthn factors, to ensure a backup device can always be enrolled in advance of more seamless backup capabilities emerging in the industry.
Consider collecting a “hint” at Webauthn registration time to help the user recall which device (phone, security key, or laptop for example) to use at authentication time.
Provide easy, user-driven key management via self-service.
Provide flexible recovery experiences in case of loss of a key, and surface meaningful information when there are multiple available authentication methods or credentials for a sign in.
Consider providing user-elected sign in method preferences, such as per-device default methods or last-successfully-used method as default for next sign in from a device.
For authenticators (platform or cross-platform)
Ensure authentication devices and platforms provide basic enumeration of which relying parties / users have been enrolled on the device (gated behind PIN/Biometric as appropriate for spec compliance). For example, Yubikeys with firmware version 5.2.3 or higher offer this via the Yubikey Manager command line “ykman fido credentials list”. This applies only to resident credentials in the Yubikey case.
For non resident credentials, the above is not feasible today because no information is stored on the authenticator device. However, if we expect the non-resident pattern to be used widely going forward, the industry should consider paving new ground by enabling the above for non resident credentials as well, based on a mapping of which relying parties this key can decrypt keys for (again, respecting and mitigating security/disclosure issues by requiring PIN/Biometric).
A note on backups of Webauthn credentials/keys
While manually enrolled hardware backup keys, and new cryptographic schemes to make maintaining those keys easier have been proposed, my gut is that a backup solution that requires incremental effort on the users part, is not going to be adopted widely enough to be valuable, and that cloud-based backups will be a more successful path. While it pains me to defeat the purpose of the private key by sending it across the internet for storage at a cloud provider, the existence of non-resident keys in the Webauthn world means that we’ve crossed that bridge already, so we may as well enjoy some further benefits from it
So now the only remaining question becomes – who should take on the key backup? It will be fragmented and difficult for each service / RP to take on backups for its own credentials, and it won’t solve the problem of “have I backed up all my creds” for the user. IDPs could do it, but not every credential is an IDP credential. This leaves technology and security companies, who have both the expertise to backup keys safely and the relationship with the authentication device(s). Microsoft, Yubico, Google, Apple, Okta etc all have the security depth and technology breadth to execute successfully on an offering to back up (and manage) users’ keys easily. And any company who has a credible authentication app would have a great entry point to introduce such a service. It would then naturally follow on from a key backup service, that a new-device-provisioning experience could then be provided, as well as other key management experiences (what keys do I have where, etc).
Webauthn for PKI professionals
The public/private key pair is at least as old as me.
The public/private key pair is at least as old as me.
A story you can skip if you want
A little over ten years ago, Microsoft decided that its enterprise PKI and directory server technologies should converge. As a result, I was one of the people re-org’d from the core operating systems division, where I was happily working on the certification authority and revocation services known collectively as Windows Server Certificate Services, to the Active Directory team, which would eventually become the Identity team responsible for Azure Active Directory.
The new girl in Identity, I tried to understand this world of authentication based on passwords, pre-shared symmetric keys, and bearer tokens which have no grounding in proof of possession. It seemed so weird to me. I never quite got it, or why it was OK. Folks I asked seemed impatient, so I stopped asking.
Years went by, we got a new CEO, and something called Next Generation Credentials (NGC) was born as a collaboration between the platform and Identity teams. NGC would eventually become known as Windows Hello for Business, based on asymmetric (public-private key pair) cryptography.
I was really happy to see the key pair embraced by Identity, and then to get to manage the implementation of Hello for Business in the product I by that time owned.
While this was happening, I was a little surprised but even more pleased to see my employer get on board with the open industry standards that would become Webauthn/FIDO2. Early in 2017 I campaigned for FIDO support to be one of the new features we targeted for my product, though unfortunately I wasn’t able to get that plan booked. Since then, the Webauthn/FIDO2 approach and set of standards has advanced even more, and I’ve become even more of an advocate for it.
Context for this article
Most Webauthn/FIDO2 articles and documents I’ve seen so far come from one of two frames of reference: either traditional identity directories or FIDO U2F, the earlier FIDO standard for strong second-factor auth. The authors therefore either assume their audience is familiar with things like LDAP, Kerberos, and username / password-based login, or with the earlier FIDO U2F protocol. They therefore either spend a bunch of time introducing the concept of asymmetric key cryptography, or they spend a bunch of time introducing the concept of keys “resident” on the authentication device.
I wanted to write a doc that describes Webauthn/FIDO2 from a PKI frame of reference. To us, neither asymmetric cryptography nor resident keys is a new concept, but several aspects of Webauthn still will be. So, here’s my take on Webauthn for PKI professionals: what’s the same, what’s different, what’s better and what has yet to be solved.
WebAuthn vs PKI
Webauthn sounds like a great new idea: using a public-private key pair for authentication, using a PIN or biometric to unlock the private key, and having the private key (optionally) resident on a removable authenticator. But these are things we’ve done for decades. Asymmetric key cryptography was discovered in the 1970’s (by all accounts I’ve read, anyway). Since then, PKI has provided one of the most secure and usable authentication technologies we have seen. The US government has known this forever, which is why they have used PKI client certificate authentication as the technology underpinning Department of Defense common access (CAC) cards. Other enterprises deploy the same technology, known simply as smart cards. So, what’s new here?
To summarize, Webauthn is not so much a new concept as a refinement: one that has the potential to extend the benefits of asymmetric key pairs to everyone, not just tech workers, defense departments, and banks. And it is even easier to use.
So, what does Webauthn have that PKI does not? And why do we need to be newly enthusiastic about it?
Both provide essential benefits of asymmetric cryptography
First, both PKI (specifically PKI for user authentication) and Webauthn provide a straightforward and secure user experience by taking advantage of the key benefits (no pun intended) of asymmetric cryptography.
Resistance to phishing, disclosure, and man-in-the-middle attacks
Because no secrets are sent over the wire, both protocols reduce the risk that credentials will be stolen/disclosed and used by bad actors. Authentication is tied instead to proof of possession of a private key. Information specific to the session and agreed upon between client and server is signed by the client to assert that proof of possession (for client certificate authentication, this is TLS session information, for Webauthn it is a random challenge generated by the website or “relying party” that is signing the user in).
Both also authenticate the server using the server’s public key and HTTPS web origin. Webauthn additionally provides a specific check of the web origin sending the authentication request and challenge against the one associated with the credential itself. This guards against phishing attacks that use a fake site that is a close misspelling of the intended domain, for example.
Resident keys
You may hear the term ‘resident key’ or ‘resident credential’, or the newer, synonymous term ‘discoverable credential’, mentioned in Webauthn/FIDO2 conversations. This simply means that the private key is physically located on the authenticator device – either a security key or the client platform itself. While this is pretty much by definition how things work in PKI world, Webauthn/FIDO2 and FIDO U2F have an alternative concept where the private key is encrypted and stored with the relying party (website or resource being signed on to) as an encrypted blob. During authentication the relying party sends the blob down to the client/authenticator, who can decrypt it with a local, device level key. The main benefit of this is that it preserves capacity on an authenticator device. Today, either model (resident/discoverable or non-resident / server-side credential) is possible and can be specified upon Webauthn credential creation using the parameter requireResidentKey (which may or may not be renamed to requireClientSideDiscoverableCredential at some point). A lot has been written about how this distinction affects the user experience, but I’ll leave that to the audience to deduce.
Again, resident keys are nothing new to PKI professionals familiar with smart card sign on. But Webauthn does introduce some new concepts to the public private key pair using world, and it offers improvements relative to many, though not all, of PKI’s challenges. Now let’s move on to a discussion of the new concepts and how Webauthn measures up to PKI.
WebAuthn Concepts
Credentials per resource
“Who’s she? they ask me
as she stumbles past me
It’s one of twenty different names, depending where she goes
but I still don’t know which one’s real”
If every place you go knows you by a different name, their ability to talk amongst themselves and figure out your patterns of movement are reduced. One of the design principles of Webauthn credentials, and one of the big differences between Webauthn and traditional PKI client certificate authentication, is that Webauthn creates and uses distinct credentials and keys for each resource.
In PKI authentication it’s common for a user to have a key pair and certificate that is marked for authentication and that they use to sign on. Mapping between the PKI credential and the user’s profile at the resource is done by matching the user’s X509 certificate subject or subject alternative name, for example, to the one in their profile at the resource. Webauthn/FIDO2 credentials are a bit more specific than this. They are enrolled per resource: a new resource means a new key pair, credential id, and even user id. The relying party will typically store/map the user’s profile directly to the credential id and associated public key information. This means a user can be expected to have many different credentials and key pairs, either on a security key, on various client platforms, resident with relying parties, or all of the above. The purpose of having multiple credentials is privacy. You have a different credential everywhere you go, so there’s less opportunity for a resource or a third party to track where you have been. However, this obviously introduces some overhead in credential management.
Departure from revocation via “block list in the sky”
A couple of years ago, I was working an IT job and trying to evangelize a security key pilot as part of the path to achieving password-less sign on. One of the more troubling objections I heard to this effort was that we couldn’t deploy the keys in production because if a user loses their key, we can’t revoke it! There are a few layers to this I’d like to unpack:
First, Webauthn does not have the same “revocation list” concept that PKI has. There is no “block list in the sky” that Webauthn relying parties check to ensure credentials are valid. Instead, each relying party has an “allow list” of credentials that are seen as valid for sign on (generally mapped to user profiles, as discussed above).
Next, there are two layers of “key” to talk about when discussing the concept of losing / revoking security keys. There is the individual key pair / credential, enrolled for each resource, of which there will probably be many on the physical security key. And then there is the physical security key itself, the authenticator device.
Regarding loss, disclosure or compromise of the per-resource key pair, while Webauthn/FIDO2 does not have the concept of revocation that PKI has, there is absolutely a way to invalidate a credential by simply removing it from the resource’s allow list and/or disassociating it from the user who registered it. While the experience may vary, Webauthn relying parties should ensure there is a way to do this, such as an “I lost my key – please forget this key” option. Of course, this scenario presumes the user knows the per-resource credential has been lost or disclosed. It’s really unlikely that this would be the case unless the hardware key was lost.
If the hardware security key (either a security key or a phone or computer with platform authenticator) is lost, then the user needs a way, absent the key, to interrogate which credentials at which resources need to be disabled. To my knowledge, tools to enable this do not yet exist.
If there were a way to be sure that no valid credentials remain on or associated with that hardware key, then the security concern would be minimal. The key could be used to enroll new credentials for anyone who found it, but this would have no impact on the original user or their accounts.
If, however, valid credentials remained on the hardware key and were not disabled at the resource (because, for example, the user couldn’t recall all credential to resource associations that were associated with the lost key), then the risk is that a finder of the key would be able to interrogate which credentials could be used and try them. This is definitely possible with existing tools, especially for resident credentials. However, mitigations include a device PIN or biometric (in the case where user verification is required) or other sign on factors (in the case in which the security key credential was enrolled as a second factor) which would have to be defeated in order for account compromise to occur.
In summary, the only case in which a found security key could successfully be used for login would be if:
The finder in physical possession of the security key was able to enumerate which resource(s) the security key had credential(s) for, AND
The credential was not disabled at the resource, AND
The resource either did not require a PIN or biometric, or the finder was able to defeat those factors, AND
The credential was enrolled as a primary / password-less factor and not as a second factor at the resource, or the finder had defeated these other factors
These conditions could absolutely occur, but in particular due to the possession factor, this is not the most likely of threat vectors.
Finally, there is an additional scenario in which a security key is found to have a security flaw as a result of manufacturing, firmware, or other defect or compromise. In this case, an entire class of security keys would be affected. Webauthn has the concept of attestation to allow relying parties to verify that a security key comes from a set of devices currently considered to be trustworthy.
Bottom line:
The ability to revoke an individual hardware security key does not currently exist in Webauthn. However, individual credentials can be disabled by the resources that registered them, the “lost security key” scenario is mitigated by several factors, and attestation provides a model to mitigate the risk of security flaws affecting entire classes of hardware security keys. Regardless of this there is not yet a great way for security key users to know how many and which credentials were associated with a lost key, for the purpose of mitigating risk of unauthorized account access. This is work the industry still needs to do.
Decentralized deployment
Webauthn embraces a decentralized, or what I call ‘BYO’, deployment philosophy. Rather than being focused on credentials that are centrally managed and provisioned by IT departments, Webauthn’s most basic protocol experiences expect that a user will use a browser, visit a site, be prompted to register or use a credential, and will then provide their own key. This is different from the model expected by most deployments of PKI or smart card credentials to users, which tended to be directed by IT departments and employers, who provide the necessary hardware and guidance to users.
The difference is subtle: many PKI scenarios enabled client-driven enrollment or auto-enrollment, and Webauthn credentials can be bulk provisioned by IT departments. The difference is one of emphasis. The most fundamental requirements for Webauthn protocol support in browsers and platforms enable a user with an un-personalized retail security key to personalize and use it with websites who support the protocol. In the PKI world, certificate / key deployment and smart card personalization often required additional software or middleware.
Where PKI had challenges
Despite its advantages, there’s a reason (or several) that PKI never became predominant outside of government/defense, banking, and certain other sectors. Overall high overhead, heavy infrastructure requirements, and certain … er … limiting design choices caused PKI to be a vast, intricate, and fragile beast. The list below will be no surprise to PKI professionals.
Hardware support
The hardware to support PKI smart cards was not built in to all PCs and laptops, let alone phones. Smart card readers and adapters, or otherwise new hardware, needed to be deployed along with the associated drivers and middleware, for smart cards to be useful.
Credential Deployment and Management
PKI key and certificate provisioning and management is costly. Whether for initial provisioning, renewal, or recovery, the choices are pretty much: in person at a security office, or via an additional certificate management infrastructure layer, or both.
Revocation
PKI’s requisite revocation infrastructure further increases the footprint and, via attempting to enforce a “block list in the sky” which may not be available or up to date, creates opportunity for denial of service and delayed enforcement when access is revoked.
X509 Certificates
In addition to the key pair, the defining characteristic of PKI has been that X509 certificates are associated with each key. Certificates contain a lot of metadata (certificate attributes and extensions with information that arrange certificates into chains for trust verification, try to help with certificate selection, and various other things) that has often been more trouble than it was worth.
Expiration
PKI certificates have a defined validity period (expressed in the X509 attributes) and must be renewed when they expire, contributing to the cost of management, and creating opportunities for denial of service
Poor user experience for credential selection
“Cert picker” user experiences in PKI have notoriously been pretty terrible, in particular because the X509 metadata isn’t sufficient to inform users of which cert to pick, and too often it isn’t sufficient to allow software to narrow the certificate choices to just one.
How WebAuthn measures up
I should tell you at this point that I believe Webauthn is the key based auth solution that can provide the benefits of PKI while avoiding the problems. That said, Webauthn does not yet have it nailed. While it has solved or mitigated many of the problems of PKI, there is some work left to do. I describe this in more detail below.
WebAuthn provides a good improvement on PKI in the following areas
Hardware support
An enormous advantage of Webauthn/FIDO2 is wide hardware and platform (OS and browser) support across all of the most common devices and platforms, so that special “readers” and associated software are not required. USB, NFC, and Lightning; Windows, Android, and iOS; Chrome, Safari, and Edge all have support for both provisioning and using Webauthn/FIDO2 credentials. I won’t do the details justice here, but check out the latest platform and browser support at caniuse.com/webauthn.
Revocation
Webauthn does not use the PKI revocation “block list in the sky” model to allow and deny access to a given credential. Rather, it uses an allow list that is specific to the relying party / website being accessed and is checked as part of Webauthn authentication. While there are some gaps in the key loss/compromise scenario currently, the removal of revocation’s costly overhead and availability challenges will make Webauthn much more deployable and maintainable than traditional PKI.
X509 Certificates
Webauthn does not use X509 certificates for user authentication. It uses only the key pair and simpler metadata including a credential ID and relying party ID. While authenticator attestation uses a traditional certificate and chain model to verify classes of FIDO2 authenticator devices, this part of the model is optional. Because the Webauthn user credential has no cert and no chain, I believe it will prove more consumable for more scenarios than traditional PKI.
Expiration
Webauthn user credentials do not expire. Once a user has registered a credential, it is valid until the user deletes it or until an admin or relying party removes the associated public key and credential info from its allow list. This will solve one of the key challenges that has plagued traditional PKI: outages due to unanticipated certificate expiration.
What is left to solve for WebAuthn
Webauthn’s strengths as a web and mobile friendly authentication protocol with broad device and platform support give me a lot of confidence in its potential for broad adoption. However, there’s a lot of work still to do to make sure we complete both the enterprise and consumer scenarios.
Credential Deployment and Management
This is an area where I would characterize Webauthn’s progress as a “mixed bag” compared to PKI.
Provisioning and use of Webauthn credentials is trending to be much easier (for the user) than PKI. This is a result of the native support described above that focuses on web (browser) based, remote, self-service “BYO” scenarios.
I have to call out, though, that Webauthn places a non-trivial burden on the resource / relying party to get the implementation (of consuming Webauthn) right and to provide a good user experience. While work is in progress in the industry, there is not yet enough good and easy-to-consume guidance for relying parties to make it so.
Aside from provisioning and credential use, there is also significant work to do to enable users to manage (find, list, delete) their Webauthn credentials. One of the defining characteristics of Webauthn – that it requires a distinct key pair for each resource and each client device – means that users will have a large number of keys. This creates the potential for a key management nightmare. Which key did I use for this site and which authenticator device does it live on? Do I have a backup key? How can these keys be kept track of? What if I need to revoke or invalidate a key? The industry will need to address key management beyond “CRUD” (create, read, update, delete) as we will see “a bazillion keys” proliferate. See A Bazillion Keys.
And there is work to do to enable enterprises to provision and manage credentials in ways that work for an organization. For example, organizations require bulk provisioning features so that administrators can configure security keys for designated resources before sending to users. Organizations also require a suite of capabilities to manage the Webauthn credential lifecycle, audit and log credential enrollment, use and other actions.
Account recovery – enterprise and consumer
If you’ve learned about Webauthn/FIDO2 credentials, you’ve probably already asked the question, or have been asked the question, what happens if I lose my security key? Currently the default answer is to ensure you “have a back-up”, and because Webauthn credentials are specific to each resource / relying party, you need to enroll a backup multiple times, for each time you enroll a credential. This is not a good enough answer.
This is a hard problem, but there are things the industry can do to provide better solutions, and several are already being actively worked on. For example, identity verification services enable remote recovery based on identity evidence such as government issued documents and a photo or video, and are based on a mobile app or website. Also, the standards community is working on new cryptographic schemes to enable backup security keys to be linked just once to a primary security key, vs needing to be enrolled for each and every resource.
In the meantime, relying parties can take some simpler, pragmatic steps. For example, as part of the user experience for Webauthn support, websites should prompt for either an additional security key or other backup enrollment factors.
Strong, remote self-service provisioning
This is a very similar problem to the above: how to “bootstrap” a higher security credential to either a brand new user or a user who currently signs on with a password, without requiring in-person verification. The identity verification services mentioned above apply to this problem space as well, though for users with existing password based accounts, many web services will consider a one time step-up security enrollment based on a password to be “good enough”. There is plenty of precedent for this in enrollment of MFA factors to password based accounts today.
User experience for credential selection
Webauthn has the promise to provide the ideal user experience with “just enough friction”, whether for credential registration, selection, or use, and to avoid the pitfalls common to the PKI experience. However there is still work to do to refine, document, and evangelize guidance to create this experience, especially when there is no username. I look forward to the progress in this area.
Consent culture
I feel like maybe we all unknowingly agreed to something in Apple’s Terms of Service
Corinne FIsher (@philanthropygal)
“I feel like maybe we all unknowingly agreed to something in Apple’s Terms of Service”
Background
A few years ago I was inspired to write the following after traveling to Europe:
Dear Europe Internet,
I know that you use cookies.
I promise to always know that you use cookies.
I will not forget.
Please stop telling me that you use cookies.
I know.
Thank you.
Later, I was able to update it as follows:
Dear Europe Internet,
I know that you use cookies.
I promise to always know that you use cookies.
I will not forget.
Please stop telling me that you use cookies.
I know.
Thank you.
More recently, I was part of a team that was building tons of apps and APIs and looking, as are we all, for a way to govern who could call whom and for what and according to whom. One way to do it is to give every app a certificate, but that’s pretty high overhead and plants a bunch of time bombs in your infrastructure. Also, it doesn’t solve the problem. It gives every app an identity (a cert) but it doesn’t solve who can call whom. Similarly, neither does OAuth, which provides clients, apps, and api/resources with identifiers and even credentials, but which lacks a specification for how the actual authorization model mapping should be built and maintained.
Industry specs and working groups are constantly developing, and I’m always looking into various drafts and working groups, but as of now I haven’t seen an industry standard for mapping user permissions to resources. The closest I can find is something called “User-managed access” or UMA, which has product implementations including ForgeRock.
The team I was on came up with a concept that was kind of cute: they called it a “dating app”. It was a way for apps/APIs to pair with each other and establish mutual permissions (not sure if it included users or not).
My boss was a bit nervous about introducing the concept of swipe-left / swipe-right into the workplace, for fear of its effect on the women-folk and our fainting couches. I refrained from telling him my previous product had solved this problem via a concept called “application groups” so …. I guess you could say we were more liberal.
The Problem
From “Principles”
It’s common for sign on to be followed by a “consent” prompt. This means a downstream resource (another website or app) will gain privileges of its own if the user clicks “Accept”. In these cases it is crucial that the auth experience enables the user to know what access is being requested and for how long. Good auth provides this, as well as an easily discoverable way to revoke or manage access after the initial consent prompt.
The pattern in effect in most sign on flows today, which primarily use OAuth and OpenID Connect (OIDC), is that an application can be granted permission to a user’s resources by means of a “consent” screen on which the user approves the app’s access by choosing Accept or similar.
This is by design. The entire purpose of OAuth/OIDC was so that sharing amongst an ecosystem of apps could happen without users giving their passwords to multiple apps or people. The problem is that a couple of issues with these consent patterns (in their current implementations) have been exploited by malicious actors. For one, it is hard for a user to determine whether a consent request is appropriate or coming from a trustworthy app. For another, consent does not tend to expire. Once a user, prompted by their OAuth authorization server for consent to allow an app to access certain resources, clicks “accept”, the authorization server tends to persist this consent such that the app has access indefinitely.
This un-ending access comes by virtue of the (potentially malicious) app being granted not only access tokens (which tend to expire within hours) but refresh tokens that enable the app to keep obtaining new access tokens for weeks or months.
An aside
Not the focus of this article, but OAuth/OIDC do a great job of specifying interoperable token mechanics, good key hygiene, and access flows that acknowledge the proliferation of mobile apps, APIs and the diversity of browsers and devices. It’s just that we’re still struggling to provide the “who can access what and for how long” part of authorization. As of this point in time, we’ve done an insufficient job of enabling the entity we call “resource owner” to actually control who (whether app or person) has access to which of their resources and for how long.
Concepts of Consent
The relevance of the term ‘consent’ in a sign on context has expanded over the years as auth patterns and flows have evolved.
What it was historically
Between ten and five years ago, most customer requests I would hear regarding consent were simply to let the user know what profile information (for example, email address) was included in the sign on token sent to the app they are signing on to. These capabilities were of particular importance to European customers.
What it has become
Increasing privacy regulations and vastly expanded sign on patterns have extended consent’s charter to something more like let the user know and control which apps can access their info and what those apps can access. This goes way beyond sign on token contents to include apps allowed to reach back into your information while you are offline. And it’s not just profile information but all information: imagine an app that not only signs you in with your Google or Microsoft account, but can access your Google Drive or Microsoft OneDrive as well, for example.
Admin vs User vs App
Consent scenarios happen at several different layers, and it may be helpful to spell them out.
First, we have “admin” consent, in which an administrator configures a permission mapping to allow a client (a mobile, browser based or web app) to call a resource (app or API). This permission mapping may also include which users and/or which scopes (subsets of resources) are allowed within each mapping.
Next, we have “user to app” consent, in which a user provides consent to authorize app A to access her own information at app B. This requires an app A to app B permission mapping, as well as an authorization model by which app B knows which of its users have authorized app A to have access to what.
Going one step further, we have “user to user” consent, which can simply be called “sharing”, in which a user authorizes not only app A but user X of app A to access their information at app B. This requires app to app as well as user to user permissions. The User Managed Access (UMA) standard, which has several implementations including ForgeRock, is an example of a model for user to user app consent.
Consent Abuse
Consent abuse attacks exploit the current state of the industry, in which an app that wants access to a user’s resources only presents the user (via their auth server) with a one-time form that is often confusing or ambiguous.
Consent abuse happens when:
A nefarious app tricks a user into releasing that user’s information for the app to access (phishing)
A nefarious app tricks a user into releasing other users’ information for the app to access (phishing + failure of the authorization model)
As mentioned above, the access is often un-expiring because of a persistent authorization policy (aka “grant”) at the auth server. The nefarious app will tend to have ongoing access, unbeknownst to the user who will need never again be troubled.
Finally, it is too often unclear for the user to know where to go to manage which apps and/or users have what access.
Another aside
It wasn’t just consent abuse – it was also a sloppy, porous permissions model that has since been changed – that caused the widely publicized Facebook / Cambridge Analytica scandal’s mass disclosure of user profile information. But failure to provide a truly useful consent experience, resulting in users unknowingly consenting to release other users’ data to a 3d party app, certainly didn’t help.
Implementation
Here are some things we in the industry can do to mitigate the tricky problem of consent and consent abuse:
Provide better consent UX
“Consent” prompts need to do a much better job of informing the user of what they are allowing and the impact of their choice. However, because we live in a world where now every website is required to present every user with a “Do you want cookies” prompt which precisely no one reads, this can’t be the only answer.
Provide easy management of app consent state
What is really required is that every identity provider and resource that persists OAuth consent grants or other similar permissions should provide an easily discoverable way for users to manage what apps (and users) have been given access to what, and to revoke and manage those privileges as needed. Again this needs to be discoverable easily – not buried in the user profile’s advanced security settings.
Consider a time bound default for consent grants
Provided we ensure a simple workflow that allows the user to re-authorize their consent upon expiration, then we should consider a validity period for consent grants (with user testing to ensure we keep down the noise factor).
Make consent more dynamic
Better than the above, like MFA the “static” consent model should be evolved to provide risk and content based consent, in which previously-consented access can be subjected to an additional consent prompt only if the behavior looks suspicious. This could be because of the frequency of access, the apparent location of clients requesting access, or anything else. This experience could be tuned much further to keep the noise factor down and address real risks.
Extend model from human-to-app access to human-to-human access
As I mention above, the concept of “sharing” can and should be overlaid on an OAuth infrastructure to provide experiences for users to control their consent grants, application and user permissions explicitly. The industry would benefit from an improvement in the level of control users have over which users and apps have access to their data, so I hope to see some success stories here.
For organizations
In the meantime, to the extent that they can, organizations should evaluate admin based consent flows and configurable consent policies, vs simply individual user based consent. Also, ensure your periodic access reviews include consent grants in scope, so that unnecessary consent is purged.
The factors we choose
As most of us know by now, there is always more than one way in: to an app, to a website, to your house.
As most of us know by now, there is always more than one way in: to an app, to a website, to your house.
That sign in page with the username and password prompt? It’s just the digital equivalent of the front door. But guess what? There’s also a back entrance, a garage door, and when all else fails a shady locksmith who only wants your mother’s maiden name.
Today’s sign in and recovery methods
Most apps and websites today provide sign in by prompting for a username and password. Many sites including most major email, social media and personal financial sites also offer one or more additional multi-factor authentication (MFA) methods based on a phone call, a text to a mobile phone, or a mobile authenticator app, for example.
If you have forgotten your username and/or password, usually you can click a link and get back into your account based on an email, “security questions” you configured when you setup the account, or recovery codes. MFA methods such as text or mobile app can be used for this as well.
Fortunately and unfortunately, these recovery mechanisms provide an alternative path to sign in. Malicious hackers can choose which access path is easier: sign in or account recovery. Instead of trying to figure out your password, they may figure out answers to your security questions, hack into your email accounts, or socially engineer cell phone service providers into redirecting service for your phone number to a phone they control. They then use these methods to access and take over your account, resetting your password.
The good news is that the set of sign on and recovery mechanisms available is evolving from predominantly password and text, to include much more secure factors such as security keys, phones and computers using WebAuthn/FIDO2 credentials.
| Pre-shared symmetric secrets (least secure) | Enrolled factors, non-key based (more secure) | Public/private key-based methods (most secure) |
|---|---|---|
| Passwords | SMS text to phone | FIDO2/Webauthn platform credential |
| Security questions | Email code or temp link | FIDO2/Webauthn security key |
| Recovery codes | Phone call | Phone app with key pair |
| Mobile app OTP code | PKI Smart Card |
In order to gain the most value from this evolution, we need to update both sign in and account recovery experiences to use multiple, secure factors.
What websites should do in the near future
In the near term, the number of sites that support MFA will continue to increase, and some will adopt non-password factors as primary authentication, as for example the site medium.com has done with their email-based sign in. Because of this, the “I forgot my password” experience will need to broaden to encompass loss of other factors, for example, “I lost access to my email”, “I lost my phone and can’t use a text or phone app”, “I lost my security key”, or simply “I’m having trouble getting into my account”. Authenticator apps themselves may help by providing backup capabilities, however resources need to account for the possibility that no backup exists, either because the user did not create one or because the authentication method itself did not easily lend itself to backups (such as private key based methods). In short, “sign in” and “recovery” experiences should be offered for each factor. If sign in requires two factors, recovery should have an equivalent or higher bar
From a security perspective, account recovery should be seen as just another sign in method, as this is the way hackers see it. Strong auth doesn’t mean much if account recovery is weak.
What sites should be thinking about for the future
In the future, the user experience for signing in will converge with the experience for account “recovery” in that the user will be asked to provide whatever factors are most optimal given their device and scenario. There will be a graded scale of factors, where “not all factors are equal”. For example, proof of possession of an asymmetric private key will be considered more secure than providing a symmetric key or password. Multiple credentials / keys from different sources will be considered more secure than a single factor, and request context (risk level based on IP address, request info, device info, etc) can be incorporated into an overall risk score that serves as a factor.
Importantly, a single factor that is stronger, such as a security key, should not be recoverable based on a single factor that is weaker, such as a password or security questions. More generally, if a user needs n factors to sign in, resources should ensure at minimum that users have at least n + 1 factors registered, and ideally should ensure that users have registered additional factors of equivalent or greater strength, to enable recovery without lessening security.
And lastly a reminder from “Principles”:
Finally, new users or users who do not succeed in the account recovery experience need a way to create a new account or to appeal access to their existing account. Good auth anticipates these needs and provides entry points into these experiences, including an experience for when all credentials are lost.
Implementation ideas
In order to make this new world a reality, resources and identity providers should build features and experiences such as the following:
Basics
Provide support for additional factors for sign in, not just passwords
Provide a recovery experience for each sign-in factor
Help users enroll for additional factors to enable recovery
Expand options and policies for non-password sign in / account recovery
Provide sign in with single, non-password factor such as a phone app or security key
Provide recovery via security keys in addition to phone apps, email, and other less secure factors such as knowledge-based questions. For less secure factors, require multiple factors for account recovery.
For enterprise identity providers
Provide configurable policy to determine how many and which factors are sufficient to reset each factor, while enforcing some baseline criteria
Provide configurable policy to govern how often factors are re-verified
Provide policies to allow configuration of which factors users can use for what (for example, accessing resources vs managing auth factors)
Provide configurable policy rules for enrolling new factor(s)
The principles of good auth
The challenge of auth is the challenge of security in general: our goals are opposite right out of the gate. Let them in, keep them out. At the same time, efficiently, at scale.
The challenge of auth is the challenge of security in general: our goals are opposite right out of the gate. Let them in, keep them out. At the same time, efficiently, at scale.
According to unsolicited feedback from the guests at a recent (but pre-pandemic, so I guess it wasn’t that recent) barbeque at my house, repeated auth and MFA prompts are some of the most maddening experiences people have with technology.
Why good auth?
Sign in is something that IT professionals, administrators, CISOs, VPs, and developers all experience daily, just like the rest of the user community. No one likes inconvenient and repeated auth prompts, especially when they don’t do a great job of protecting resources and providing security. We get that things need to be protected, and we want to be part of the solution, just not if the experience sucks. And we don’t want to find out that we’ve unwittingly given all of our Facebook friends’ Equifax information to Russian bots (again).
This is why I decided to write out a set of “principles of good auth” (sorry for the grandiose naming). It’s my attempt to define some tenets we can hopefully all agree on across protocols and implementations, so that we’re cognizant of the trade-offs, and instead of getting mired in the ongoing argument of “security wants more prompts and users want less,” we can work toward some common goals.
So here we go: the Principles of Good Auth …
Good auth has a user experience (UX)
Over the past 20 years I’ve heard software engineers, architects, and executives espouse the gospel that “the user should not have to know,” and that “the best UX is no UX”. This is true for many if not most technology scenarios, but good auth cannot be 100% “transparent” or invisible. Not when a person is making access control decisions and choosing when and where to provide their credential information. There must be a clear experience that lets them know what is being accessed, by whom, and for how long. In short, access control decisions need to be explicit.
And there’s another reason that having a user experience is crucial, specifically for accessing and using sign in credentials. Consider your home or car keys. Those keys are obviously very important in your life, and they are not “transparent” or invisible. We can see and touch our keys. We know what they are for. And so we develop good habits around them. We most likely have muscle memory built around checking for our keys before we leave the house, work, gym, etc. Most of us probably know where a set of spare keys are stashed as well. This relationship we have with our keys enables us to keep track of them, to keep them protected and available. If our keys were somehow invisible, or if we didn’t interact with them very often or understand how they worked, this would not be the case. Basically, keys and credentials are different from other technical artifacts in that the “friction” or trouble taken to interact with them has a good result: it trains us to make better choices.
Good auth employs intelligent risk/threat mitigation
The internet of 2022 is one of extremes: for example, most websites interrupt each new user with a popup to explain that “we use cookies”, which is not news because every website does. Meanwhile, authenticated sites and services routinely trade user information with each other without the user knowing at all (see Consent Culture). And for workers, MFA prompts for each desktop, network and app lead to frustration and a tendency to “just approve everything”.
This one may be obvious, but good auth respects the context of a sign-in: for example, what’s being accessed, from where, how the sign-in was authenticated, the privilege level of the user, and environmental risk information; and it uses this information rather than resorting to simplistic rules such as prompts for every new resource, session time limits, or at the other extreme, troubling users just once and then never again. If something new is being requested from a previously consented website, the user should have the chance to provide new, informed consent. But if a new website is requesting a low level of access that multiple other websites likely already use, then maybe the user does not need to be bothered. For workers or for higher risk consumer scenarios such as shopping or financial transactions, the overall risk of the scenario should inform the frequency and experience of auth prompts. As the industry progresses, these experiences should be refined continuously, based on finer grained information, and evolve to trouble users only when the level of security or privacy risk merits it.
Good auth avoids methods that are known to be subject to common attacks
The security landscape is fast-moving enough without starting out in a deficit. Phishing, disclosure, and man-in-the-middle attacks are common ways to breach passwords, OTP codes, and other common auth methods. Good auth should embrace methods sufficiently resistant to the most common attacks.
Today this means avoiding factors that can be intercepted, disclosed, and used remotely without detection. Specifically, this means reducing the use of persisted symmetric shared secrets and bearer tokens, passwords, one time codes (OTP), API tokens and other secrets not bound to a proof of possession of a private key.
Good auth respects the practical realities of peoples’ lives
Good auth not only has an intelligent user experience, it has one that considers human factors such as peoples’ relationships with their phones, their ability or inability to carry phones or other items into work or school, their tolerance for wearables, their sense of privacy and/or aversion to biometrics, and their level of ability or disability.
Corporate security organizations will have their recommendations about what is the most secure authentication factor, but getting the broader population to adopt more secure practices necessitates meeting people where they are. A less secure factor that will be adopted by more of the population is better than nothing and is better than a highly secure factor which people will not use, will use incorrectly, or will attempt to find ways around.
Good auth helps the user to recognize it
The auth experience is one of the most sensitive in technology. Good auth respects the contract between the user and the “user agent” (usually an app or browser) and helps the user by giving them clear visual cues to help them determine if the interaction is safe. Good auth provides a consistent experience that helps the user to spot anomalies and/or warning signs of things like phishing or fraud.
Good auth guides the user to choose the authentication method most suitable for their device and scenario
Whether creating, accessing, or recovering access to an account, whether from a phone or laptop, app or browser, whether the account is for banking, social media, work, entertainment or shopping, the auth experience should guide the user to the best authentication method for their scenario. This could be a built-in authenticator, a security key, a phone app, a password, or something else. This applies to sign in but also enrollment and recovery scenarios. For example, when signing on from a phone to an account that was enrolled from a computer, it makes sense to guide the user to “enroll their phone” for sign on based on the on board PIN or biometric.
Learning from historically bad (for example PKI “cert picker”) user experiences, a good auth experience should surface meaningful information when there are multiple available authentication methods or credentials that are similarly suitable for a scenario. “Meaningful information” is of course subjective, but in general the experience should ensure that the information displayed for method or credential is distinct and that the easiest to use is prioritized. Providing hints based on information the user provided at enrollment time, “my security key” or similar, can help if done carefully. Hints for users are also hints for attackers, but with a secure factor such as a FIDO2 authenticator, the minimal information in the hint does not offer much help to an attacker who is not in possession of the device. (See Webauthn for PKI professionals).
Good auth treats credential enrollment and recovery, not just sign-in, as a first class experience
There isn’t just one way to sign in. For most apps and websites, you can either sign in or click something like an “I forgot my password” link, also known as account recovery, to get back into the account based on other information. Good auth makes sure the security of these experiences is consistent with the security of sign in and that users can easily enter the experience they need and that they have the credentials to use.
The auth experience should also account for common variants such as “I’m on a new computer or phone”, for example, by enabling a fallback method (relative to the ideal method for the device.) If I’m on a new phone, I may not have initialized and registered the phone app or platform authenticator. Similarly, if I’m on a new computer I may not have registered my device. There should be an easy entry point to enrollment of a suggested auth method for the new device, for example by identity verification, use of backup methods, or use of a previously enrolled device.
Finally, new users or users who do not succeed in the account recovery experience need a way to create a new account or to appeal access to their existing account. Good auth anticipates these needs and provides entry points into these experiences, including an experience for when all credentials are lost. (see The Factors We Choose).
Good auth recognizes that initial sign in is just the “front door” and that auth must be examined ongoing
Good auth recognizes that after a user signs in, a lot of things can change. The user’s location or authorization level could change easily, as could the security status of their device. Within an app, API or resource there are usually multiple sub-resources and authorization levels. Access authorized on initial sign in should be specific and minimal, and once signed in, if access to an additional or higher privileged resource is requested, or if environmental risk factors change, auth should be re-examined. (see Consent Culture, The Factors We Choose).
Good auth has clear, configurable, time-bound consent
It’s common for sign on to be followed by a “consent” prompt. This means a downstream resource (another website or app) will gain privileges of its own if the user clicks “Accept”. In these cases it is crucial that the auth experience enables the user to know what access is being requested and for how long. Good auth provides this, as well as an easily discoverable way to revoke or manage access after the initial consent prompt. (see Consent Culture).
Why “auth”?
If you ask me what I focus on in tech, I’ll tend to say “auth”, a subset of identity, which is itself a subset of information security. I define “auth” as the process, technology, and user experience of “getting in” and accessing resources. This includes sign in / authentication, authorization / consent, ongoing session management
If you ask me what I focus on in tech, I’ll tend to say “auth”, a subset of identity, which is itself a subset of information security. I define “auth” as the process, technology, and user experience of “getting in” and accessing resources. This includes sign in / authentication, authorization / consent, ongoing session management (how long you are signed in and when you have to re-auth), and account recovery. The more standard industry term “identity” includes many things I won’t do justice here (identity management, governance, entitlements management, regulatory compliance, auditing, privileged access management, etc) because they are boring.
Introduction
Introductions are so annoying. Why isn’t the prologue just chapter 1? What is the author trying to prove? The length of their backstory? The depth or complexity of their work? I’m not sure. It seems so self-important. Picture it: Redmond, Washington, 2010. A young identity professional is dealing with the aftermath of the great recession…
Introductions are so annoying. Why isn’t the prologue just chapter 1? What is the author trying to prove? The length of their backstory? The depth or complexity of their work? I’m not sure. It seems so self-important.
Picture it: Redmond, Washington, 2010. A young identity professional is dealing with the aftermath of the great recession…
Just kidding.
It was somewhere between 2006 and 2008, I think (please don’t try to pin me down on dates – the last 20 years are kind of a hazy blur), when I learned that Microsoft planned to create a version of Active Directory in the sky … er … cloud. This cloud was also where Office 365 was being conceived.
A couple of years later, I ended up in the business of connecting company networks to this cloud.
I remember thinking that this directory-in-the-sky was not necessary. The existing on premises identity systems could easily authenticate users and send claims to Office 365. No need to create redundant shadow accounts in the cloud.
I was technically correct. Also, I should never, ever, be put in charge of the business side of a software behemoth.
Like, not ever.